

What Features Make It Easy To Manipulate This Imported Data?
This commodity was published every bit a role of the Information Scientific discipline Blogathon
Introduction
Spreadsheets or Excel is the foremost and most adaptive way of exploring a dataset. It can help in making necessary changes to the datatypes, creating new features, sorting information, and creating new features out of already available features.
Post-obit the same lines, Mito is a Jupyter-Lab extension and Python library that makes it super easy to manipulate data in the spreadsheet environment with GUI support and much more than. In this article cum guide, I volition explain:
- How to properly set up Mito
- How to debug installation errors
- Usage of various features offered by the Mito
- How this library generates Python equivalent code for all the changes done on the dataset

Installing Mito
Mito is a Python Library and can be installed via the pip package manager. It requires Python three.vi and in a higher place version. As well, Nodejs, which is a JavaScript runtime environment should be installed on your organization.
I want to mention that you should install this package in a separate environment (virtual surroundings) to avoid any dependency mistake. Let's get through the installation steps (run these commands in the concluding).
i. Create an surround
I am using Conda to create a new environment. You can also utilize Python'south "venv" for creating virtual environments.
conda create -due north mitoenv python=iii.viii
2. Activate the environment
conda activate mitoenv
iii. Install Mito via pip
pip install mitoinstaller
4. Run the Mito installer
python -m mitoinstaller install
This process will take a while to install and prepare up the Mito.
5. Start the Jupyter lab
jupyter lab
A quick fix
When you kickoff the Jupyter lab, yous may get this type of mistake:
. . . File "c:userslenovoanaconda3envsmitoenvlibsite-packagesjupyter_corepaths.py", line 387, in win32_restrict_file_to_user import win32api ImportError: DLL load failed while importing win32api: The specified module could not exist found.
To fix this error, only run the following command:
pip install --upgrade pywin32==225
If you face other difficulties, feel complimentary to comment downwards below. I would be happy to assist.
MitoSheets Interface
In the Jupyter lab, create a new notebook and initialize the Mitosheet:
import mitosheet mitosheet.canvas()
For the get-go fourth dimension, you volition be prompted to enter your e-mail address for signup:
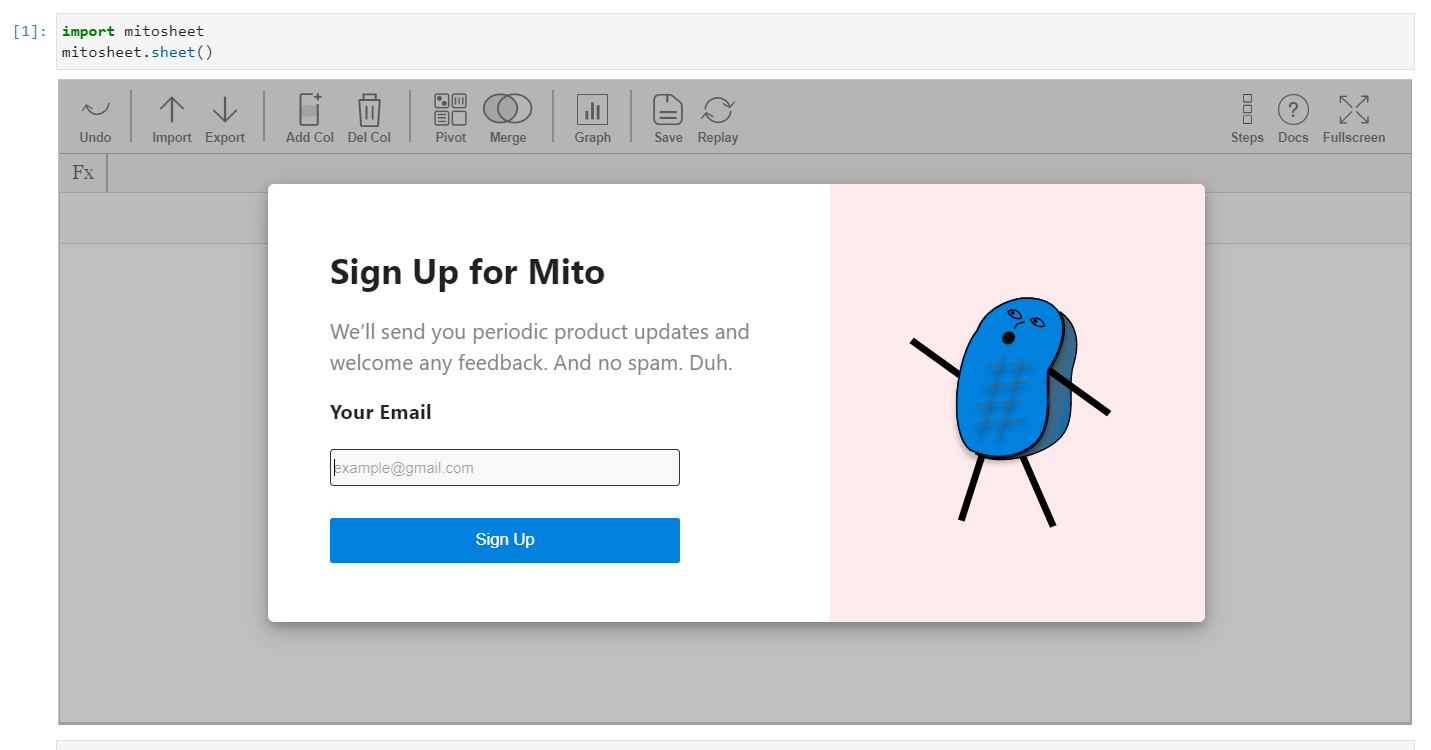
Beginning-time setup screen (Screenshot from notebook)
After filling up the basics, you will be redirected to the GUI spreadsheet. Let's observe all the features of this interface and discuss how the changes are converted to Python equivalent code.
Loading the Dataset
To load a dataset in MitoSheets, simply click on Import. And so you lot will take two options:
- Add together a file from the current binder: This will list all the CSV files in the electric current directory and you volition be able to select them from the dropdown menu.
- Add together the file past the path of the file: This will add only that detail file.
See this in activeness:

If you wait at the cell below this, you volition find out that the Python equivalent lawmaking to import a dataset using Pandas has been generated with proper comments!

This is the power of Mito, every activeness you have in your Mitosheet will be converted to Python equivalent lawmaking! Let's explore all the features of Mito in detail.
Calculation and Deleting Columns
Just like in excel and spreadsheets, you tin add a new column that might exist created from the existing columns or features. To perform this action in Mito, but click on the "Add Col" button. The column volition be added next to the currently selected cavalcade. Initially, the column proper noun will be an alphabet and all the values of the column will be cipher.
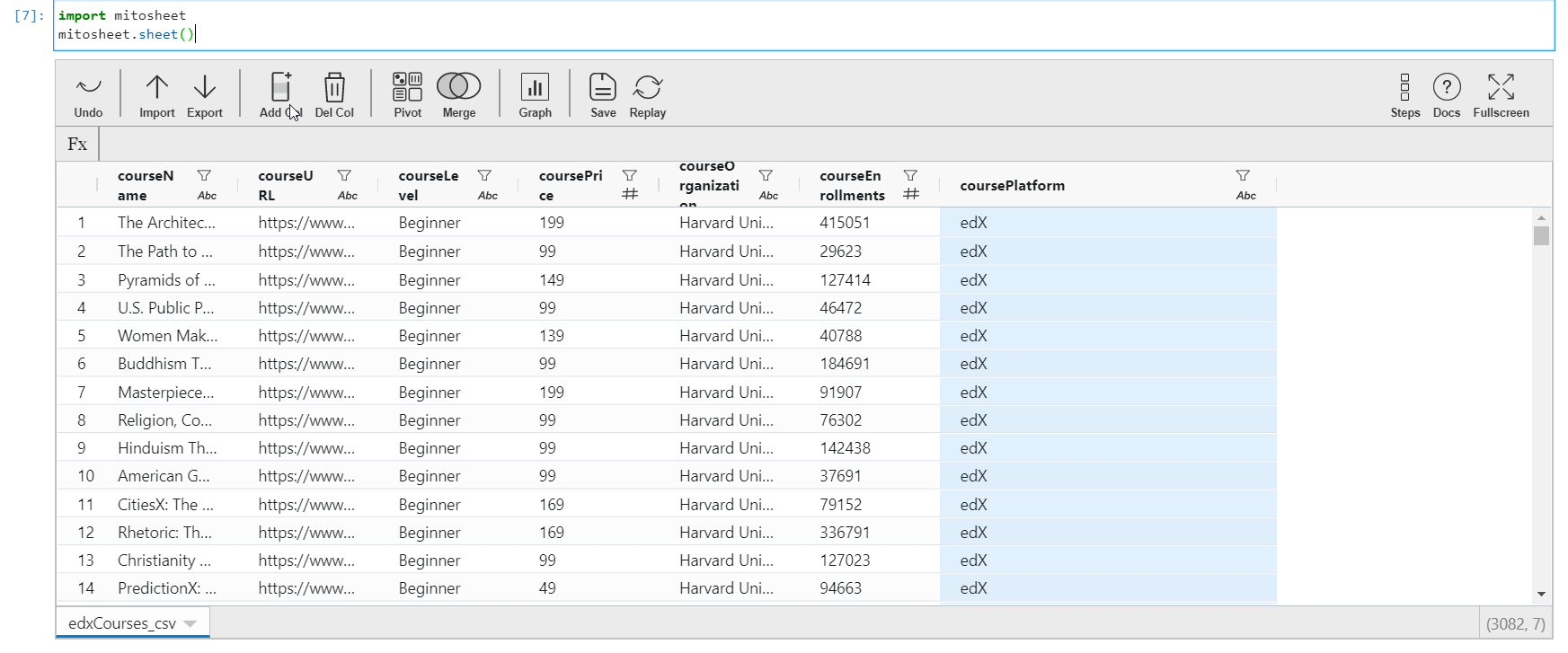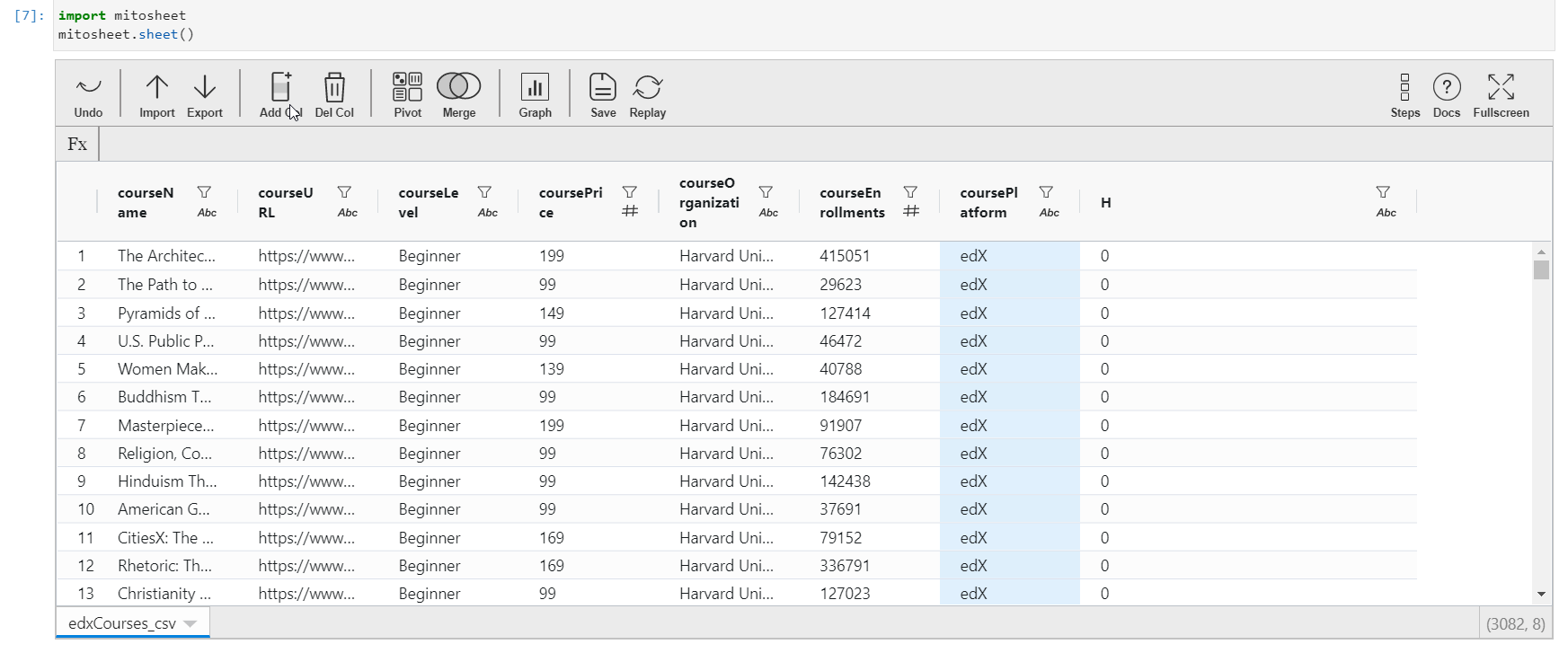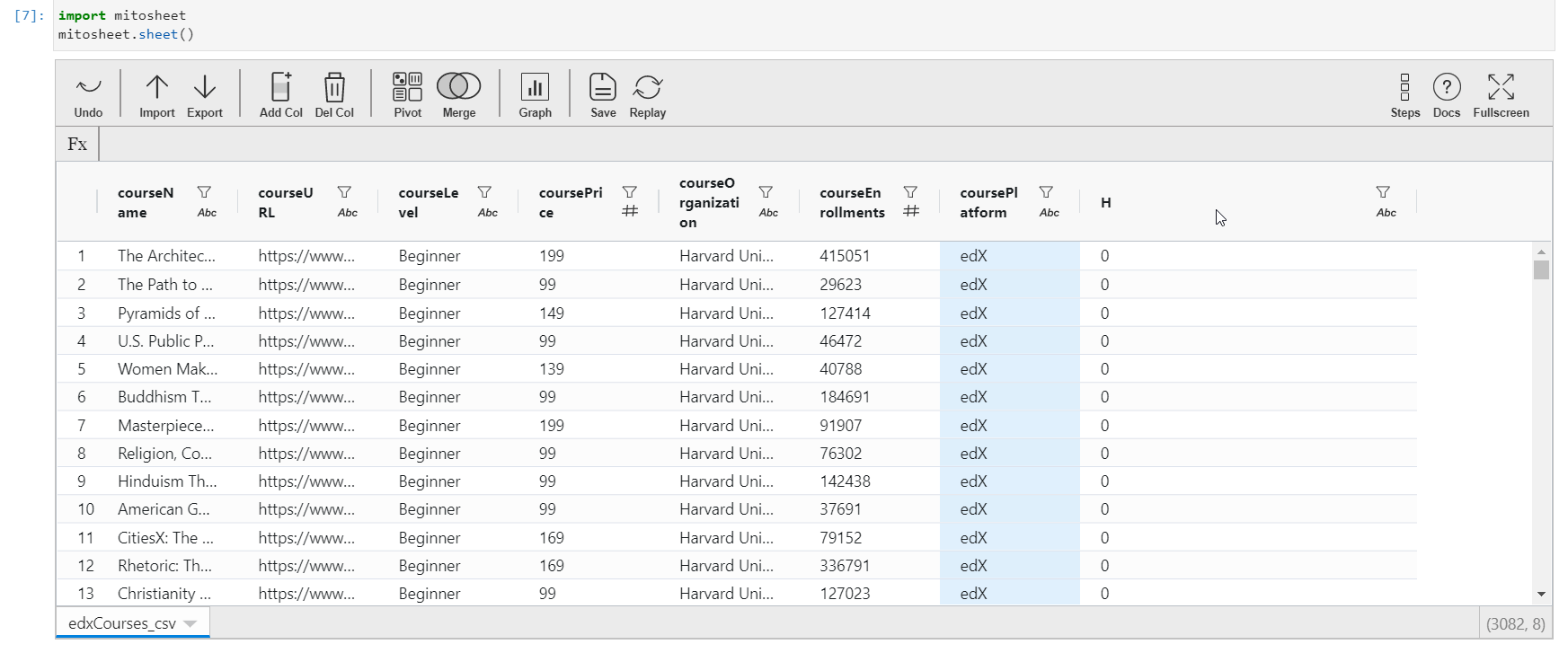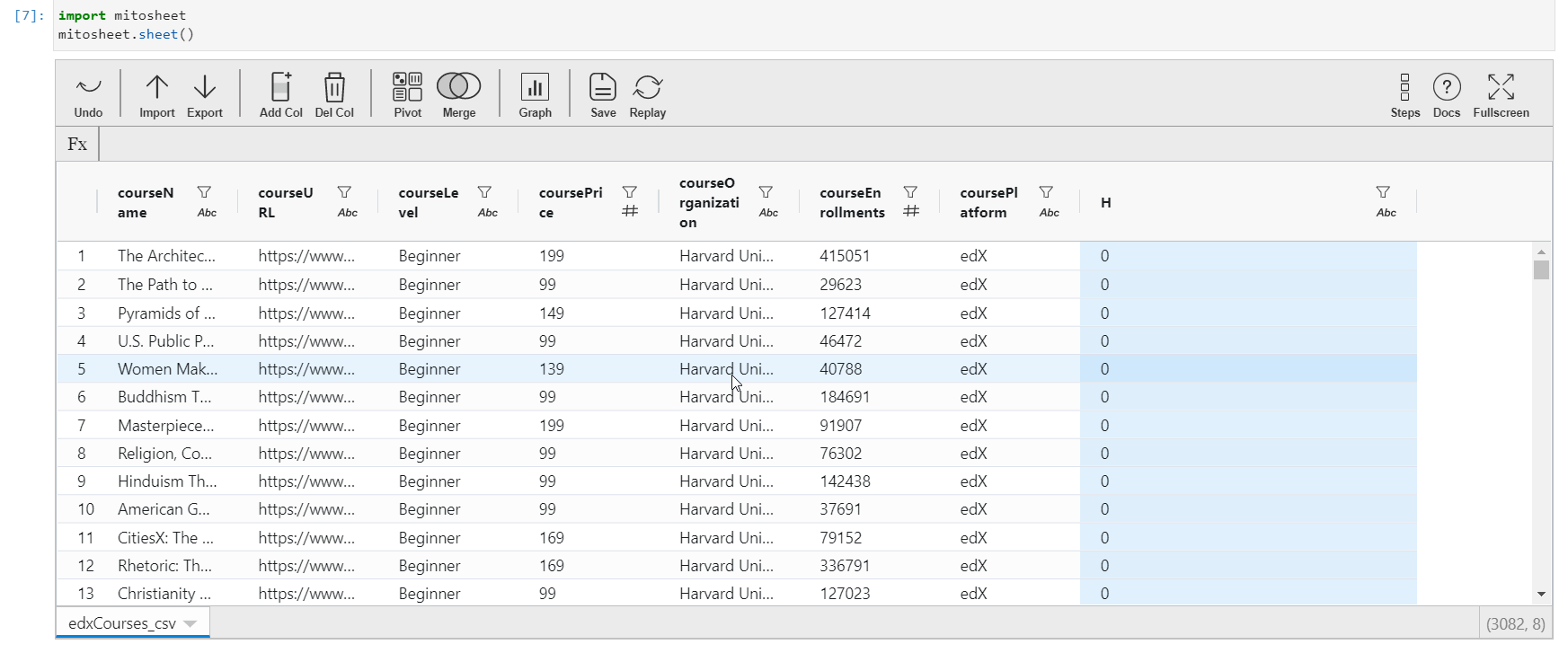
To edit the contents of this new column,
- Click on the new column name (The allotted alphabet)
- A sidebar carte du jour will pop up where you tin edit the name of the column.
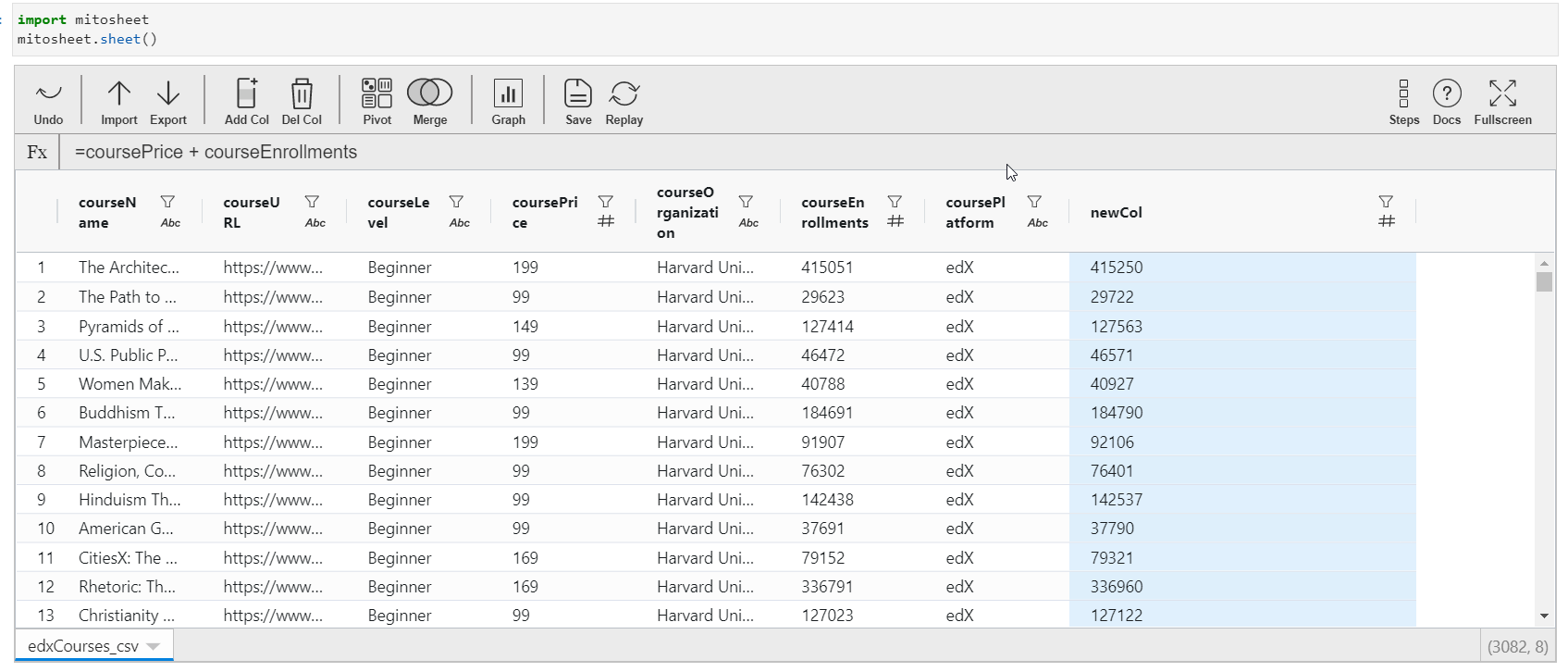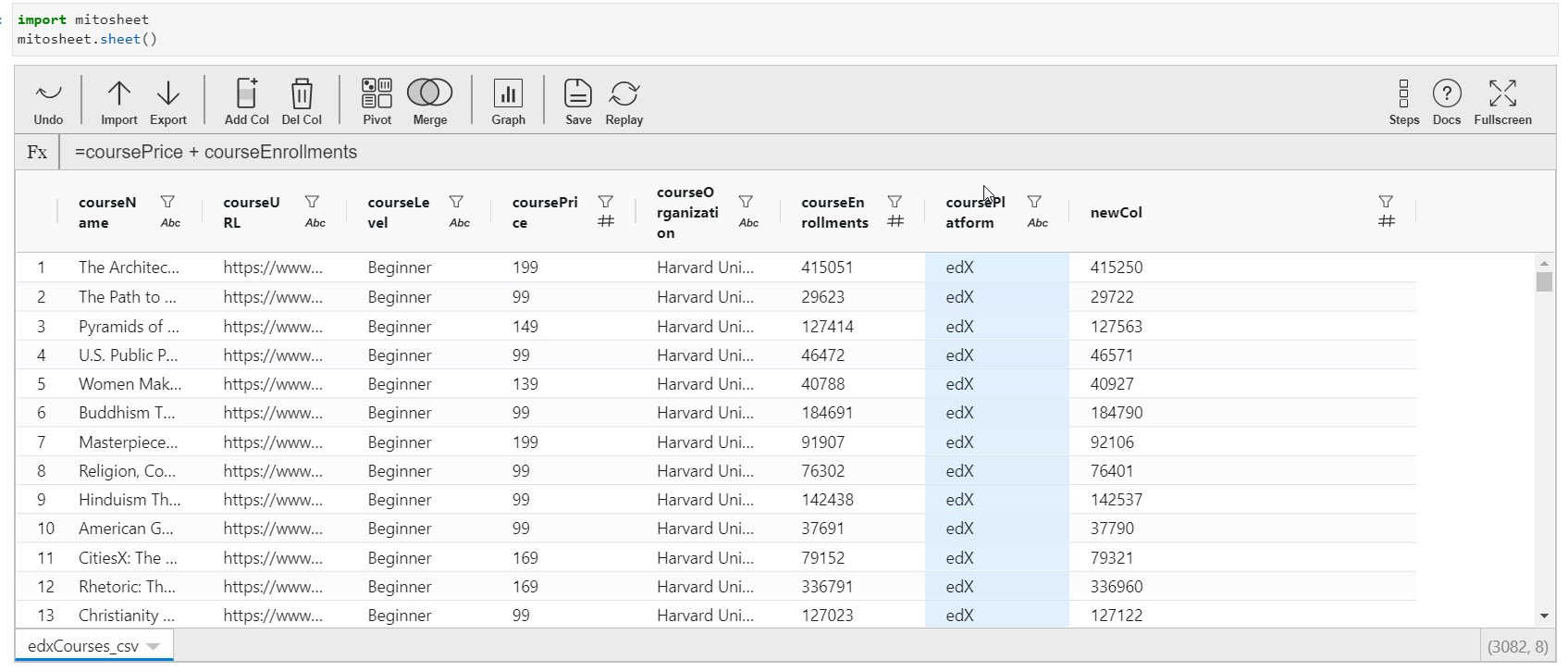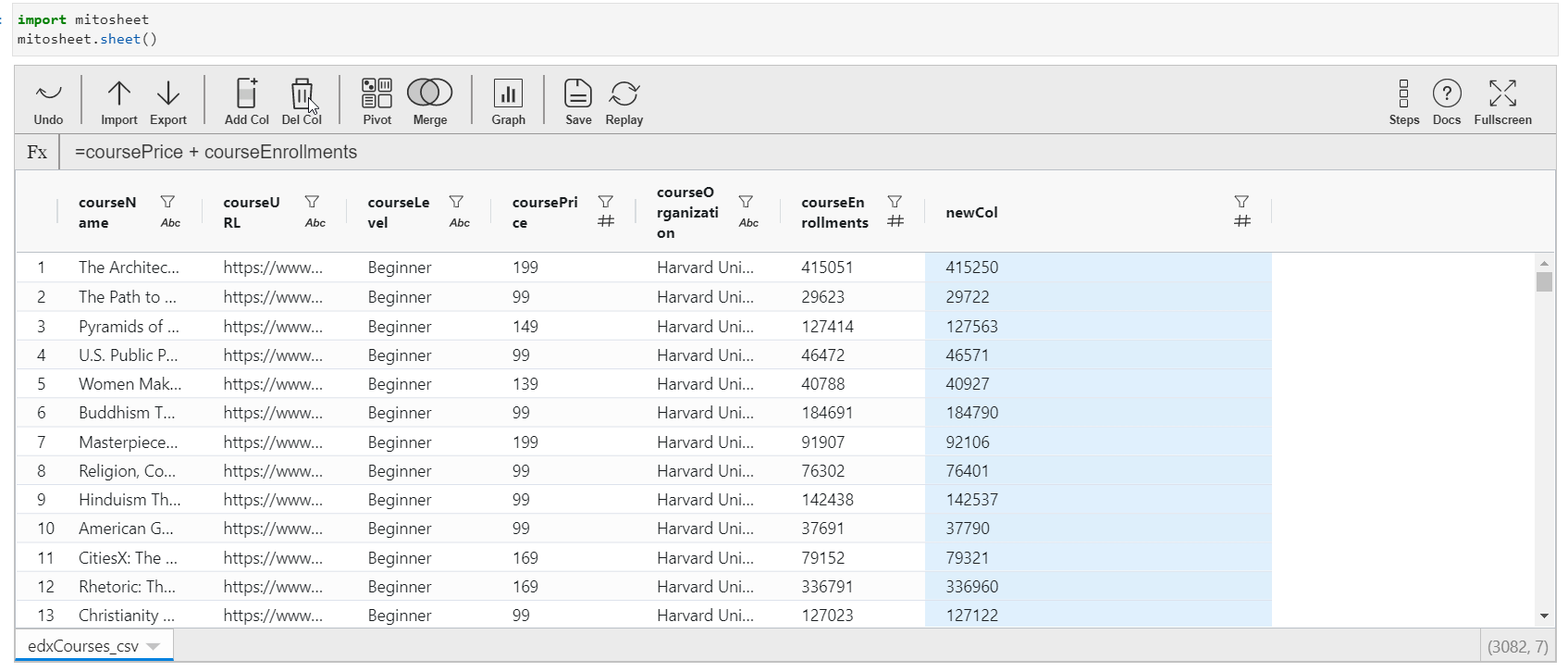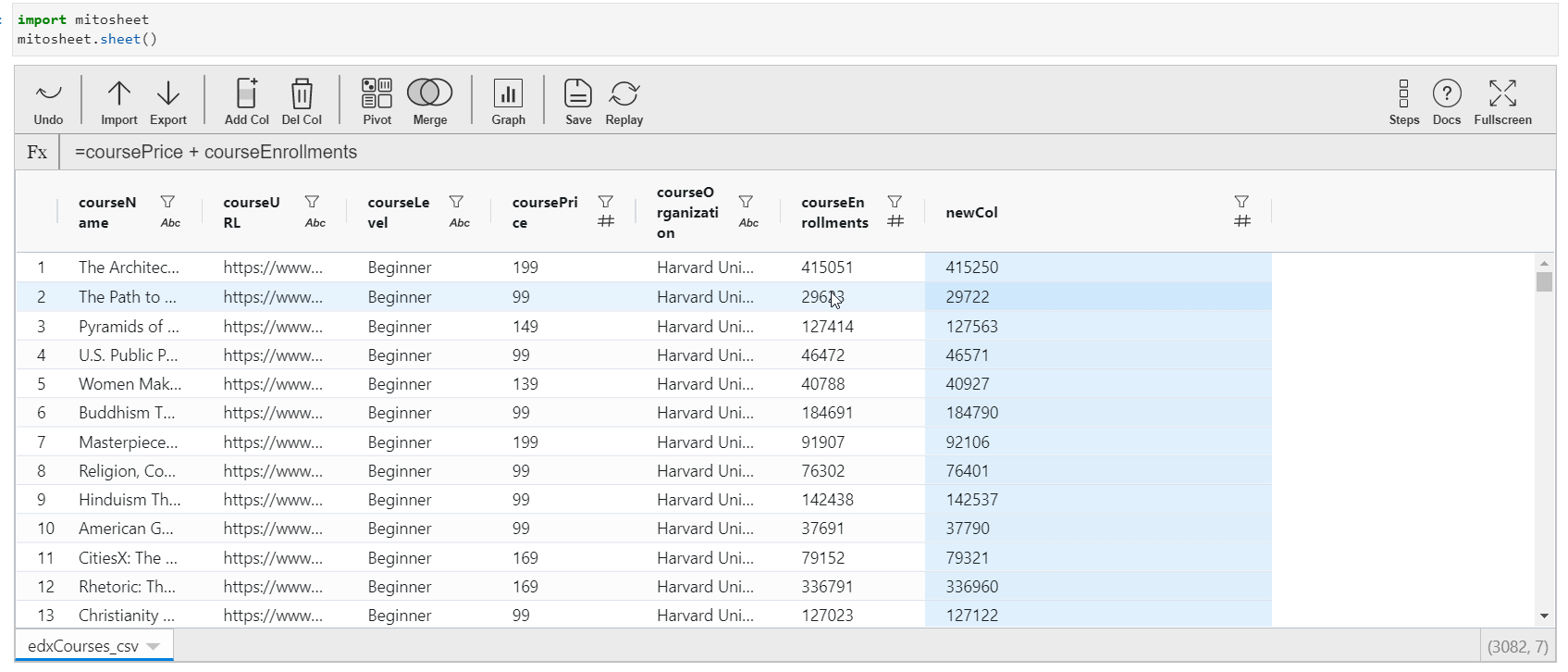
- To update the contents of the cavalcade, click on whatsoever cell of this cavalcade, and assign the value. You can either assign a constant value or create values out of the existing features of the dataset. For creating values from existing columns, direct call the column name with operators to exist performed.
- The data type of the new column is inverse according to the value assigned.
The GIF beneath describes all the things mentioned above:
Similarly, to delete whatsoever cavalcade,
- Select any column past clicking on it.
- Click on "Del Col" and that particular cavalcade will be deleted from the dataset.
The Python equivalent code with proper comments is generated in the next cell for the actions performed is:
# MITO Code START (DO NOT EDIT) from mitosheet import * # Import necessary functions from Mito register_analysis('UUID-7bf77d26-84f4-48ed-b389-3f7a3b729753') # Let Mito know which assay is being run # Imported edxCourses.csv import pandas as pd edxCourses_csv = pd.read_csv('edxCourses.csv') # Added cavalcade H to edxCourses_csv edxCourses_csv.insert(seven, 'H', 0) # Renamed H to newCol in edxCourses_csv edxCourses_csv.rename(columns={"H": "newCol"}, inplace=True) # Set newCol in edxCourses_csv to =coursePrice + courseEnrollments edxCourses_csv['newCol'] = edxCourses_csv['coursePrice'] + edxCourses_csv['courseEnrollments'] # Deleted column newCol from edxCourses_csv edxCourses_csv.drop('newCol', axis=1, inplace=True) # MITO CODE END (Practise Non EDIT) Create Pin Tables
A pivot table is an important excel office that summarizes the numeric variables based on one more chiselled feature. To create such a tabular array using Mito,
- Click on "Pivot" and select the source dataset (by default the CSV loaded)
- Select the rows, columns, and value cavalcade for the pivot table. You tin too select the aggregation office for the values cavalcade. All the options such equally sum, mean, median, min, max, count, and standard difference are available.
- After selecting all the necessary fields, you volition get a dissever table containing the Pin table implementation.
The GIF beneath demonstrates how to create a Pivot table for the "mean" assemblage function:

Generated Python code for this:
# MITO Lawmaking START (Practise NOT EDIT) from mitosheet import * # Import necessary functions from Mito register_analysis('UUID-a35246c0-e0dc-436b-8667-076d4f08e0c1') # Let Mito know which analysis is being run # Imported edxCourses.csv import pandas as pd edxCourses_csv = pd.read_csv('edxCourses.csv') # Pivoted edxCourses_csv into df2 pivot_table = edxCourses_csv.pivot_table( index=['courseOrganization'], values=['coursePrice'], aggfunc={'coursePrice': 'mean'} ) # Reset the cavalcade proper noun and the indexes df2 = pivot_table.rename_axis(None, axis=i).reset_index() # MITO CODE Finish (DO NOT EDIT) Merging Two Datasets
Merging datasets is an essential part of data science projects. More often than not, the datasets are divided among diverse tables so as to increase the accessibility and readability of information. Merging in Mitosheets is easy.
- Click on "Merge" and select the information sources.
- You need to specify the keys to which this merger should be done.
- You tin also select the columns from the data sources to be retained afterward the merger. Past default, all the columns volition be retained in the merged dataset.
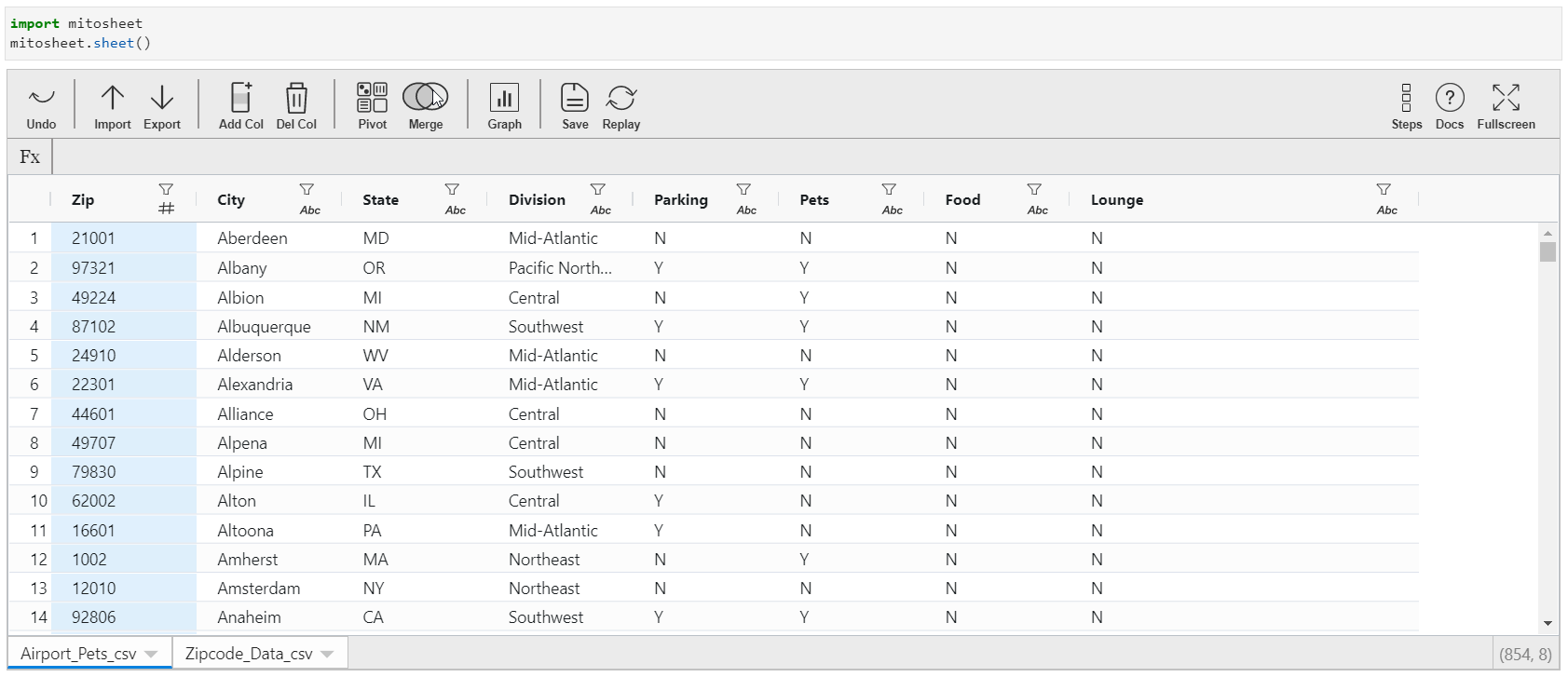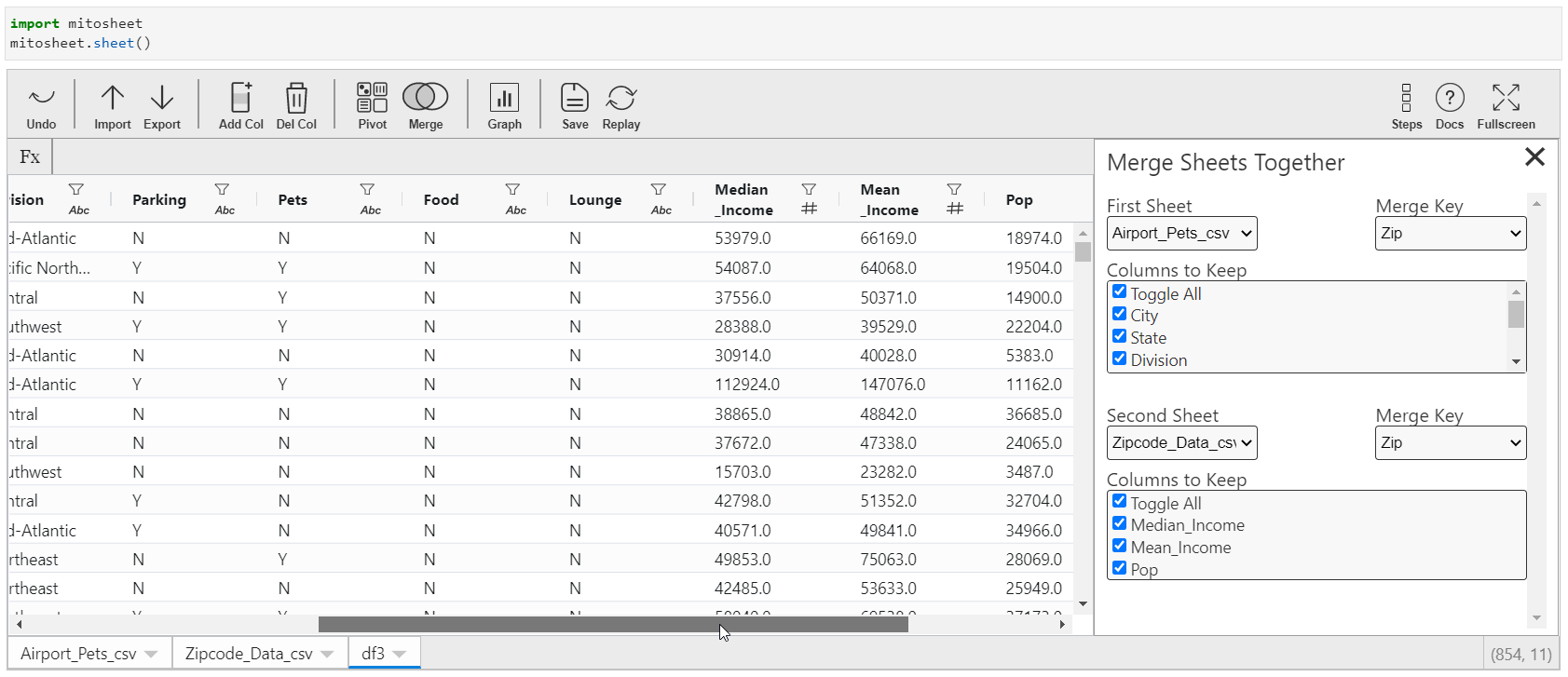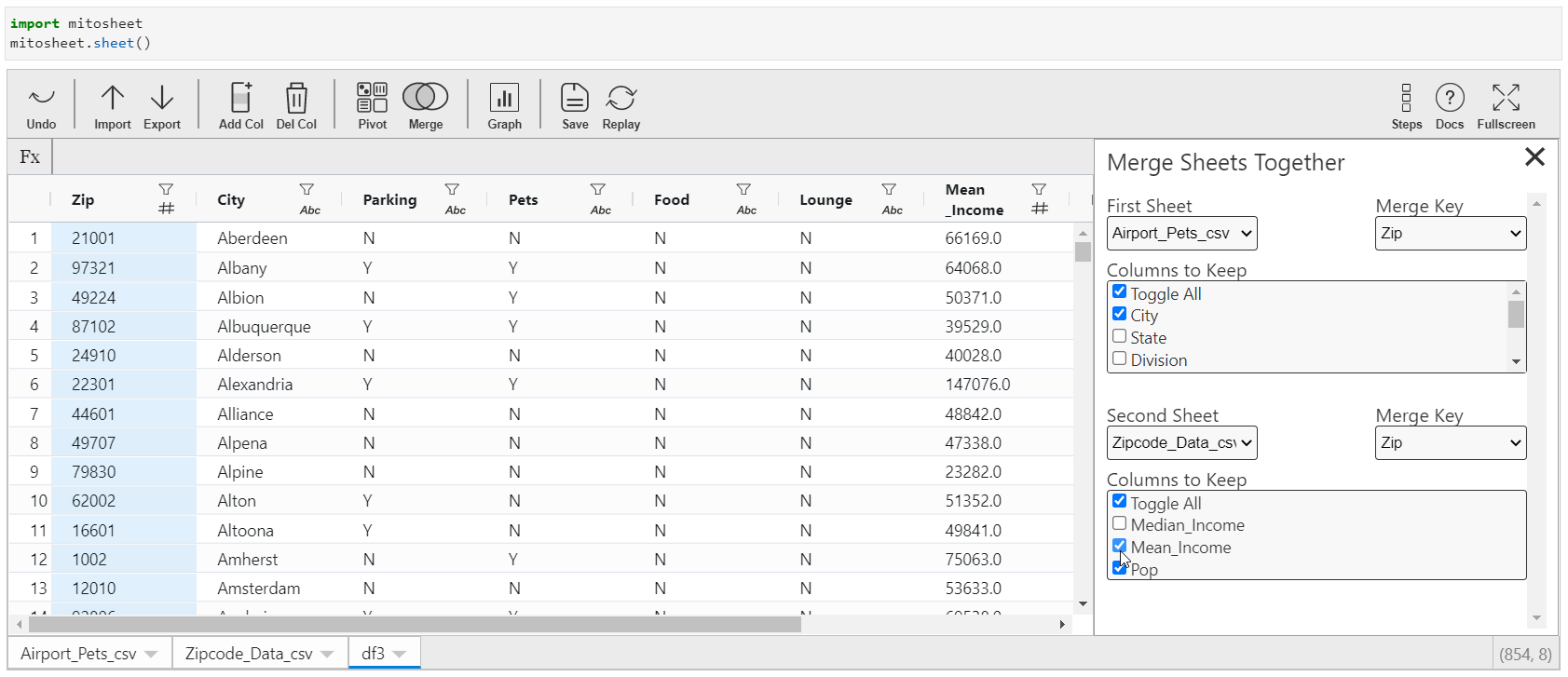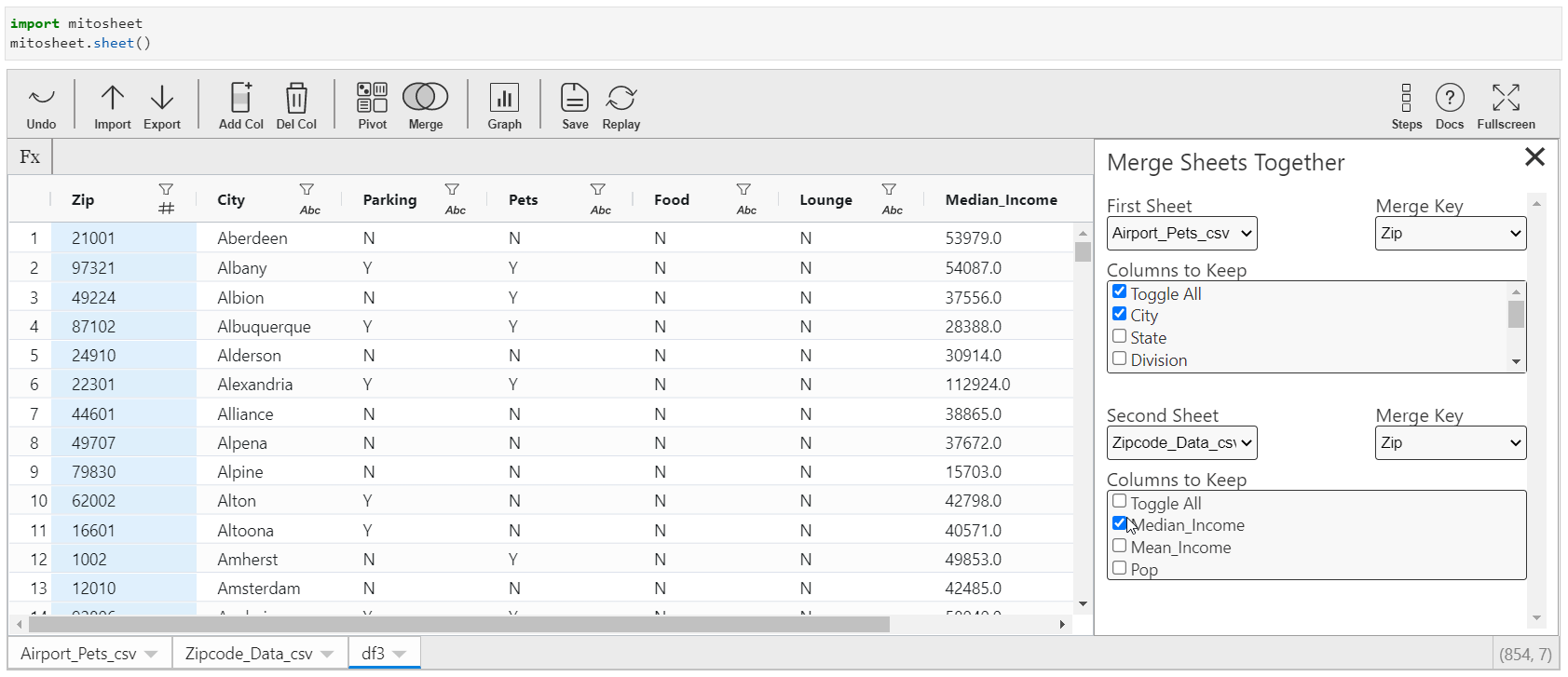
Python Equivalent:
# MITO Code START (Practice NOT EDIT) from mitosheet import * # Import necessary functions from Mito register_analysis('UUID-88ac4a92-062f-4ed8-a55d-729394975740') # Permit Mito know which analysis is being run # Imported Drome-Pets.csv, Zipcode-Data.csv import pandas every bit pd Airport_Pets_csv = pd.read_csv('Airport-Pets.csv') Zipcode_Data_csv = pd.read_csv('Zipcode-Data.csv') # Merged Airport_Pets_csv and Zipcode_Data_csv temp_df = Zipcode_Data_csv.drop_duplicates(subset='Zip') Airport_Pets_csv_tmp = Airport_Pets_csv.drop(['State', 'Division'], axis=1) Zipcode_Data_csv_tmp = temp_df.drib(['Mean_Income', 'Pop'], axis=1) df3 = Airport_Pets_csv_tmp.merge(Zipcode_Data_csv_tmp, left_on=['Zippo'], right_on=['Zip'], how='left', suffixes=['_Airport_Pets_csv', '_Zipcode_Data_csv']) # MITO CODE Terminate (Practice NOT EDIT) Modifying Column Data types, sorting and filtering
You tin change the existing columns data types, sort columns in ascending or descending order, or filter them via boundary conditions. The process to implement these steps in Mito is easy and can be done via the GUI itself past selecting the onscreen options.
- Click on the desired cavalcade
- You will be presented with a listing of data types. You can choose whatsoever datatype from the dropdown according to your requirement and that data type will be applied to the whole column.
- Side by side, you lot can sort the information in ascending or descending order past selecting the provided choices.
- You tin besides filter your data with custom filters.
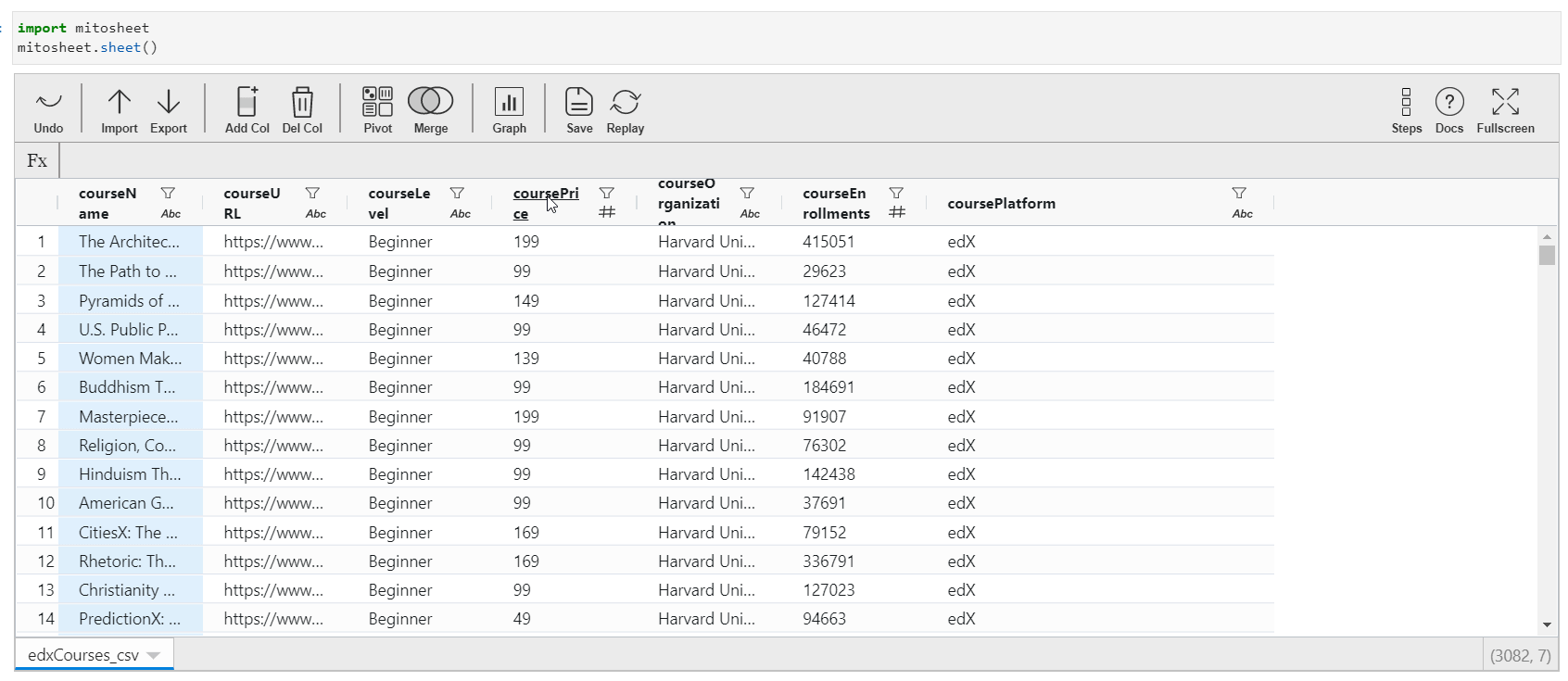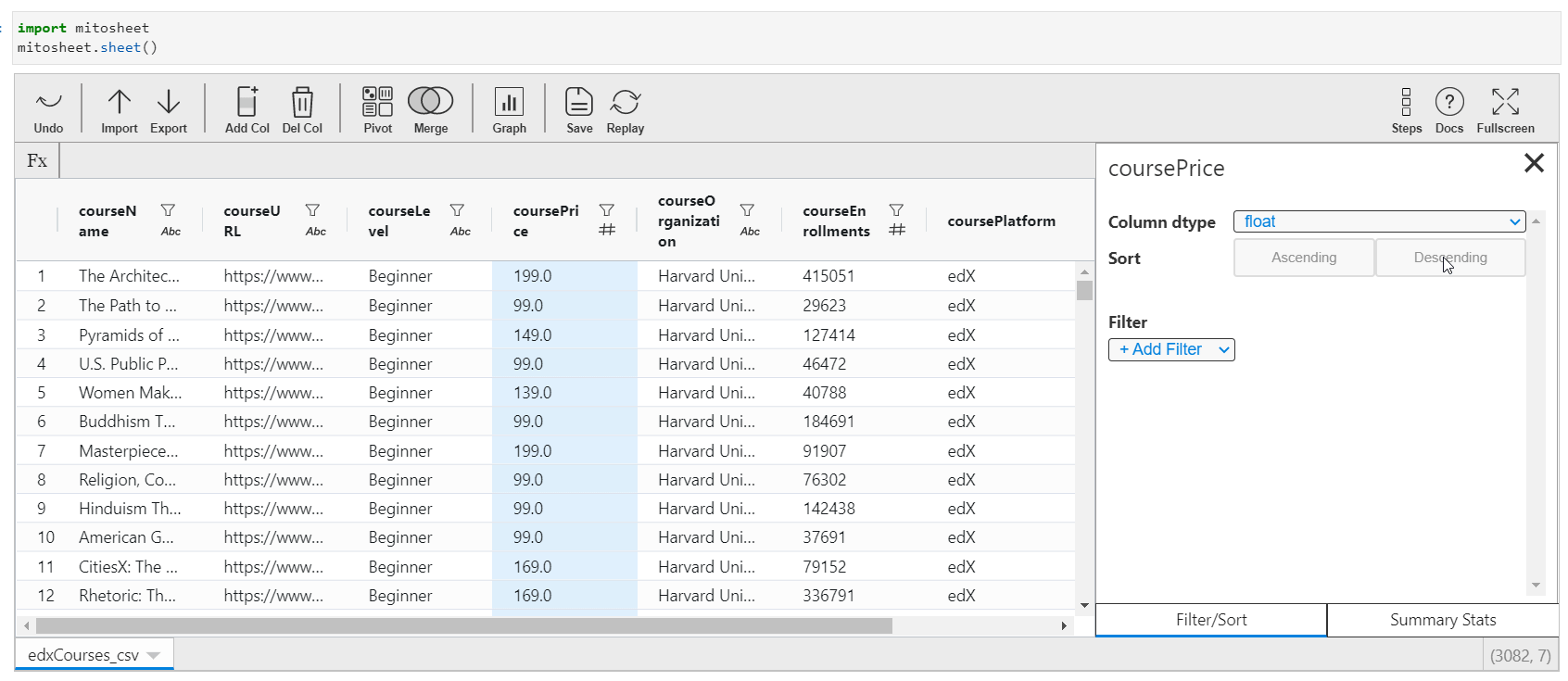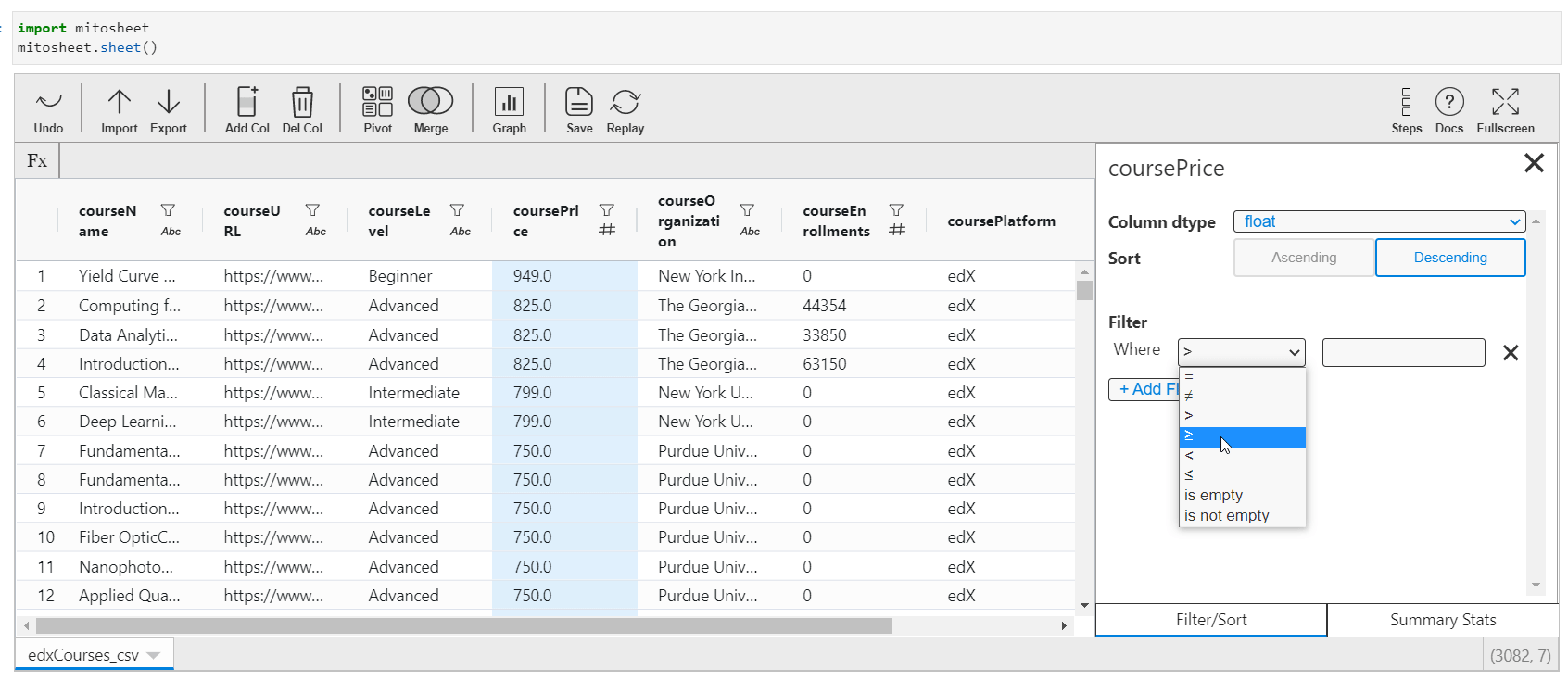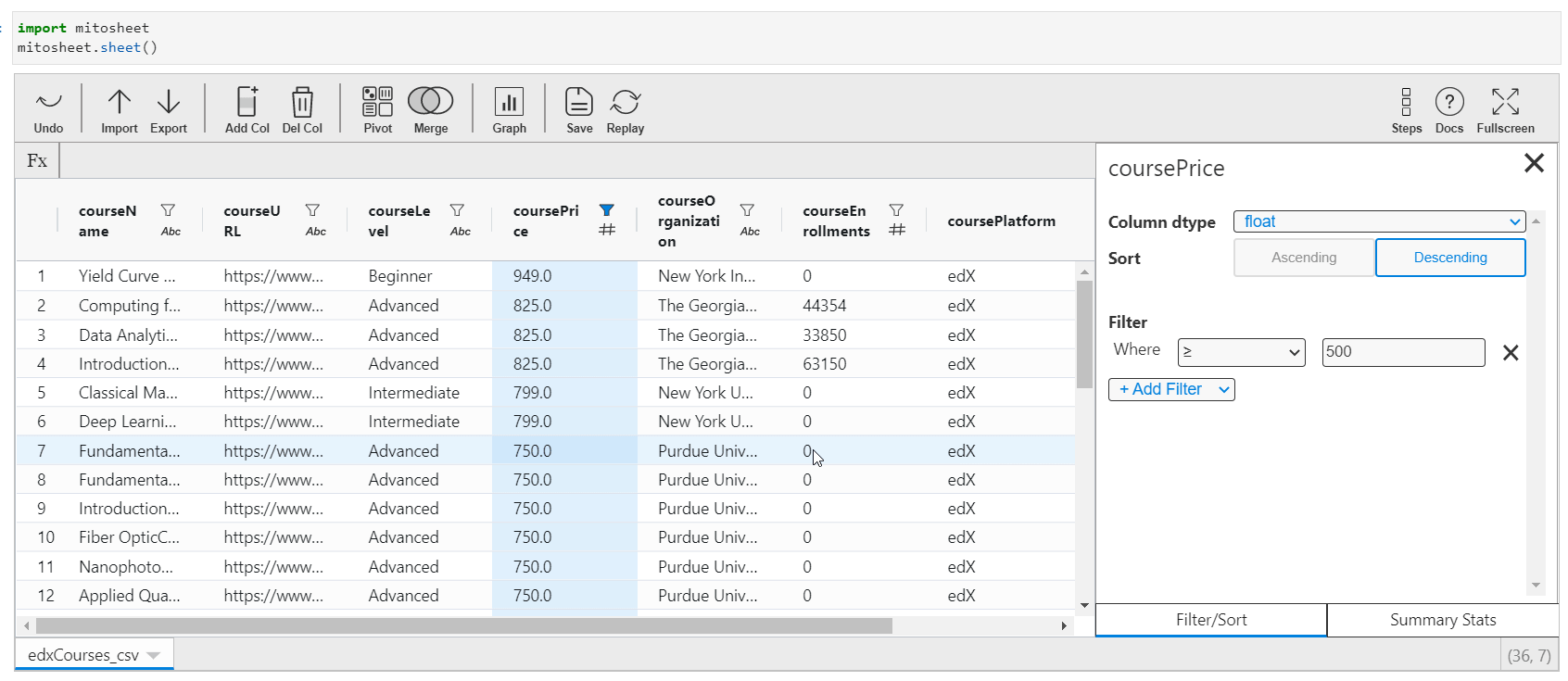
Python code:
# MITO CODE START (DO NOT EDIT) from mitosheet import * # Import necessary functions from Mito register_analysis('UUID-cc414267-d9aa-4017-8890-ee3b7461c15b') # Allow Mito know which assay is beingness run # Imported edxCourses.csv import pandas as pd edxCourses_csv = pd.read_csv('edxCourses.csv') # Inverse coursePrice from int64 to float edxCourses_csv['coursePrice'] = edxCourses_csv['coursePrice'].astype('float') # Sorted coursePrice in edxCourses_csv in descending order edxCourses_csv = edxCourses_csv.sort_values(by='coursePrice', ascending=Faux, na_position='commencement') edxCourses_csv = edxCourses_csv.reset_index(drib=True) # Filtered coursePrice in edxCourses_csv edxCourses_csv = edxCourses_csv[edxCourses_csv['coursePrice'] >= 500] edxCourses_csv = edxCourses_csv.reset_index(drop=Truthful) # MITO Code Terminate (DO NOT EDIT) Graphs and Stats Generation
You can likewise generate graphs right in this extension without coding the plotting logic. By default, all the plots generated by this extension are made using Plotly. That means that plots are interactive and can be modified on the fly. One thing I noticed is that the code for graphs is not nowadays in the adjacent cell (Peradventure developers push this in a afterwards update)
There are two types of Graphs that tin can exist generated using Mito:
1. By tapping the graphs button
Yous volition be presented with a sidebar carte du jour to make the selections for the blazon of graph and the corresponding axes to exist selected.
ii. By tapping the column proper name
When you tap the cavalcade name from the spreadsheet, the filters and sorting options are visible. Only if you navigate to "Summary Stats", a line plot or bar plot, depending upon the type of variable is displayed along with the summary of the variable. This summary changes for text and no text variables.
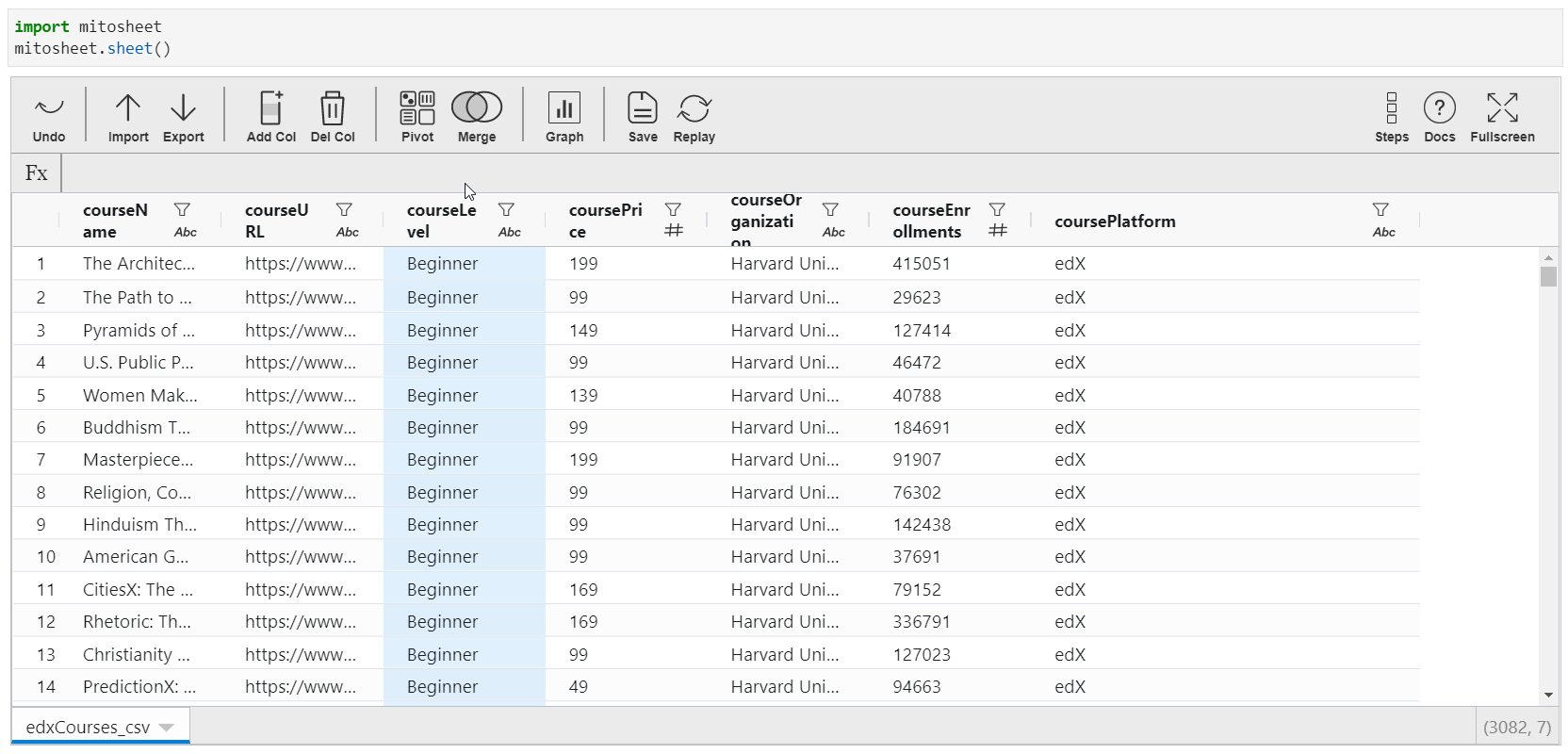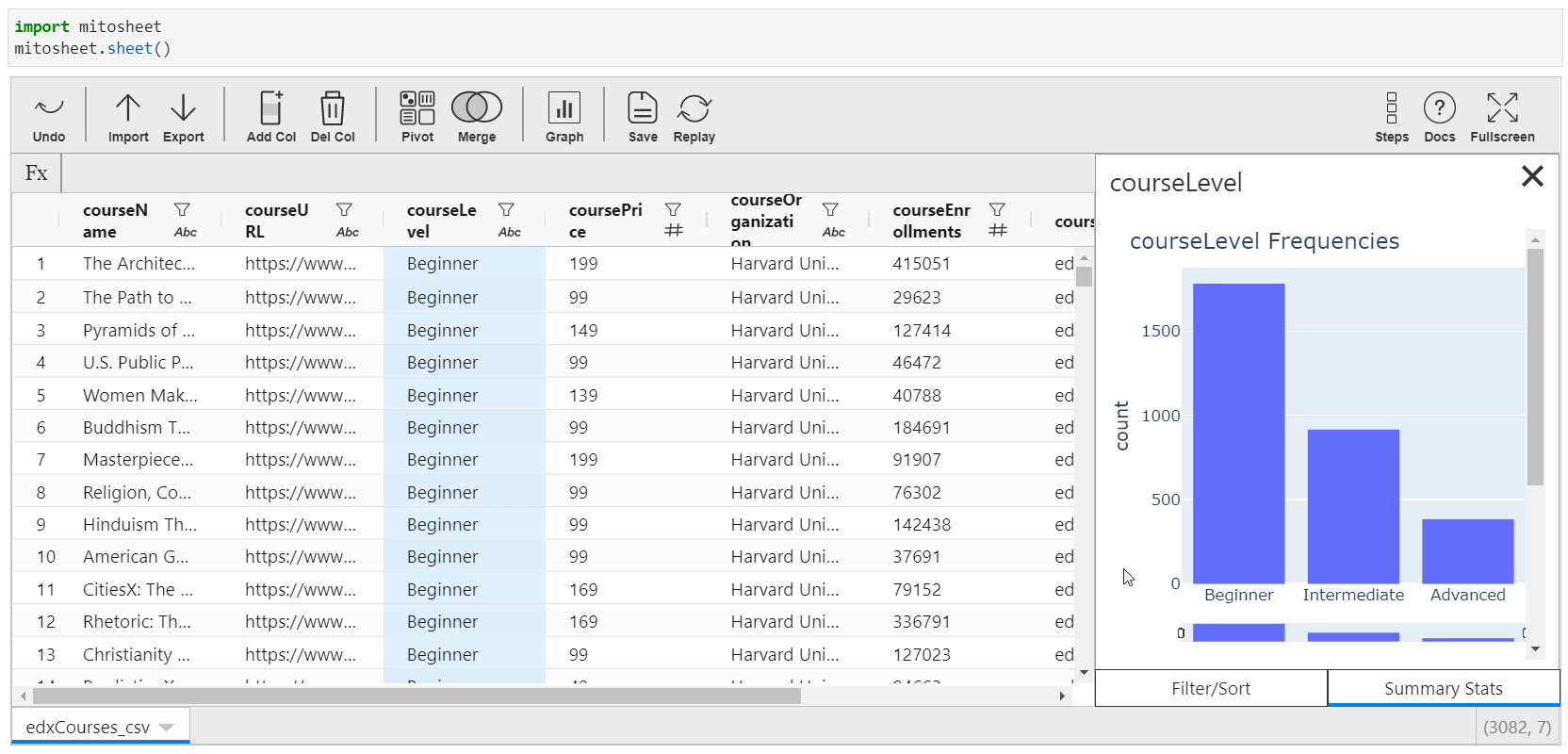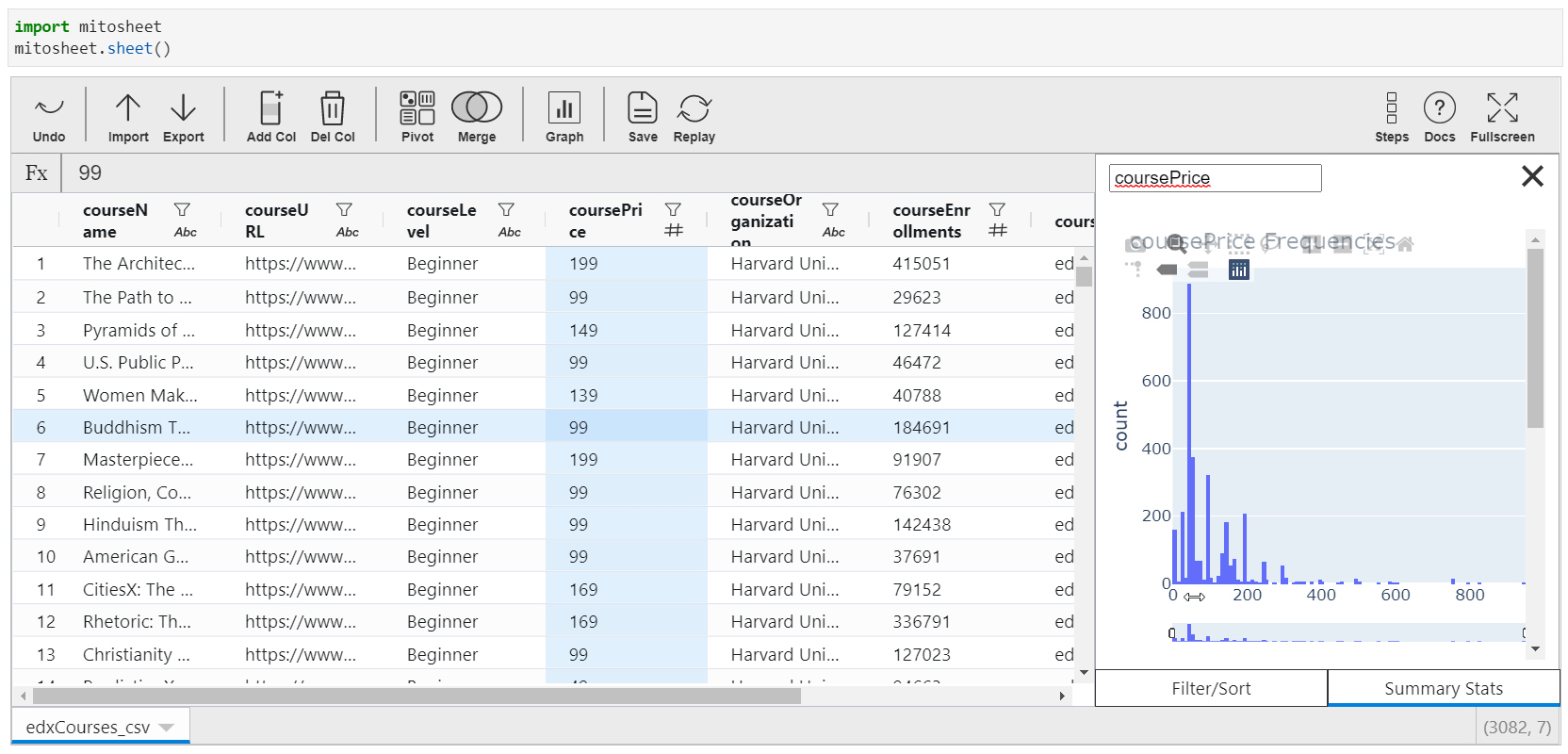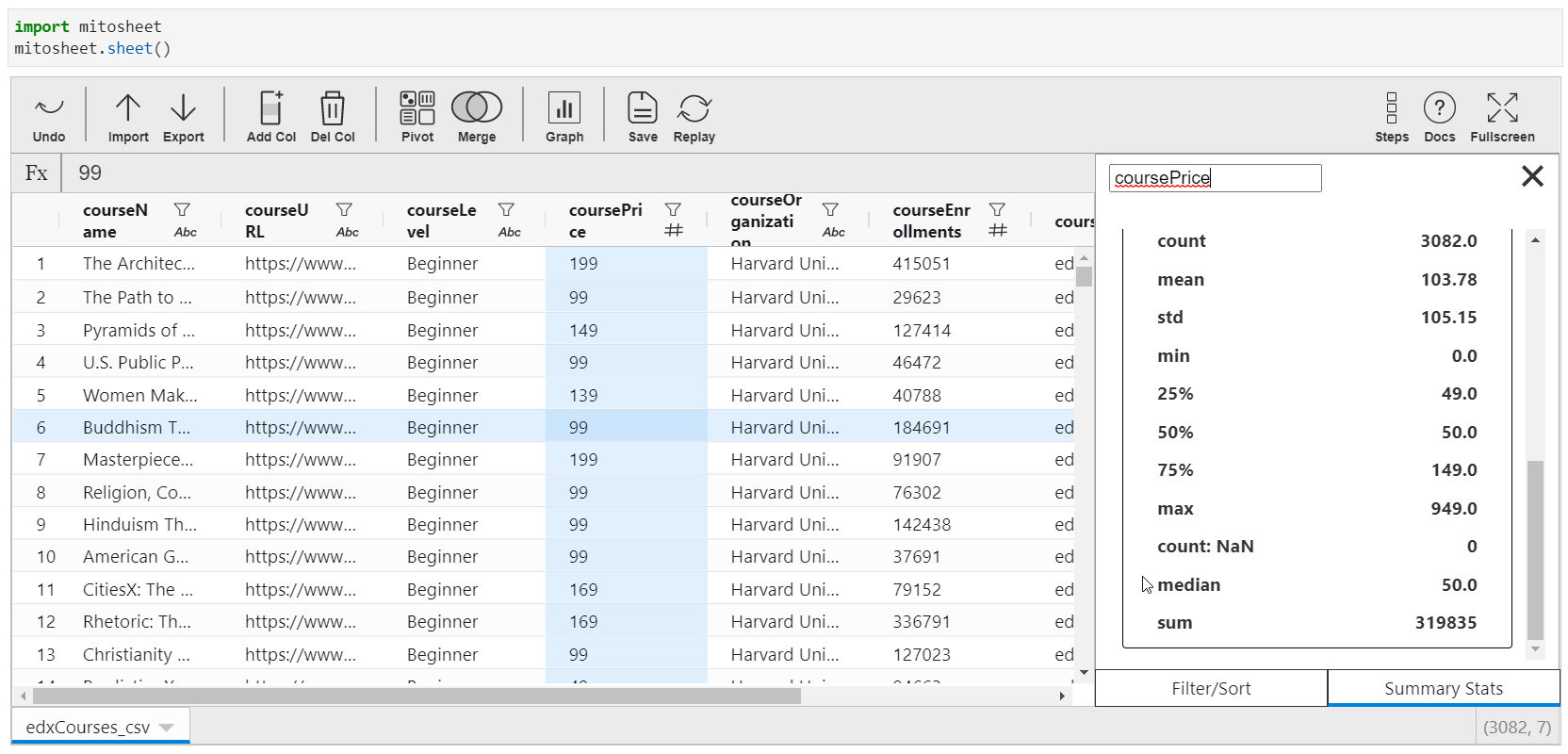
Save and Replay
All the transformations done on the dataset can be saved and used for other similar datasets. This takes the class of a macro or VBA in Excel. The aforementioned tin exist done via these functions also.

Screenshot from Author notebook
Backtracking all the Steps performed
This feature is the most interesting one. You can actually trace out all the transformations practical in the Mito-canvass. A list of all the operations is available with appropriate titles.
Also, y'all can view that particular pace! This means that suppose you have changed some columns and so deleted them. You can pace dorsum to the time when information technology was not deleted.
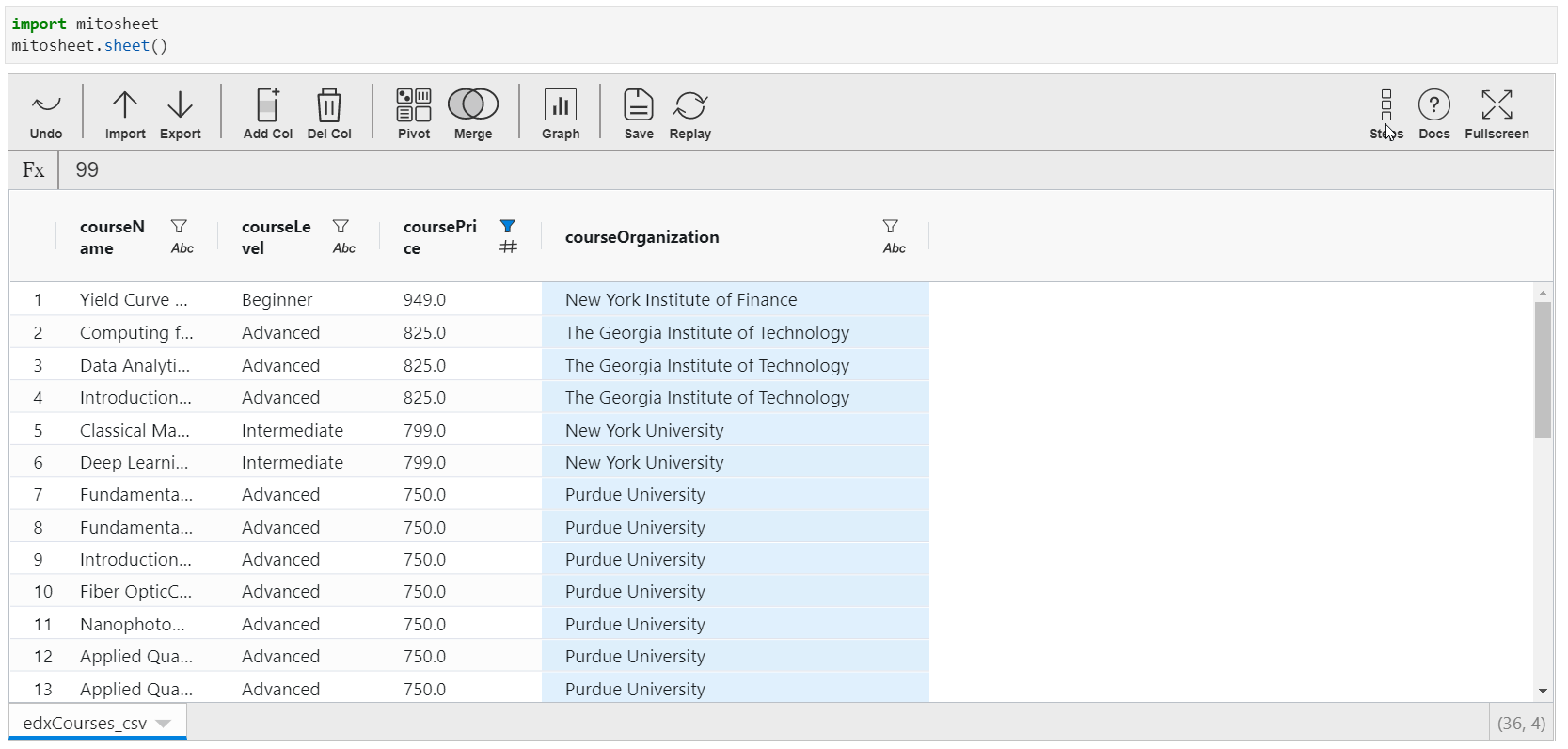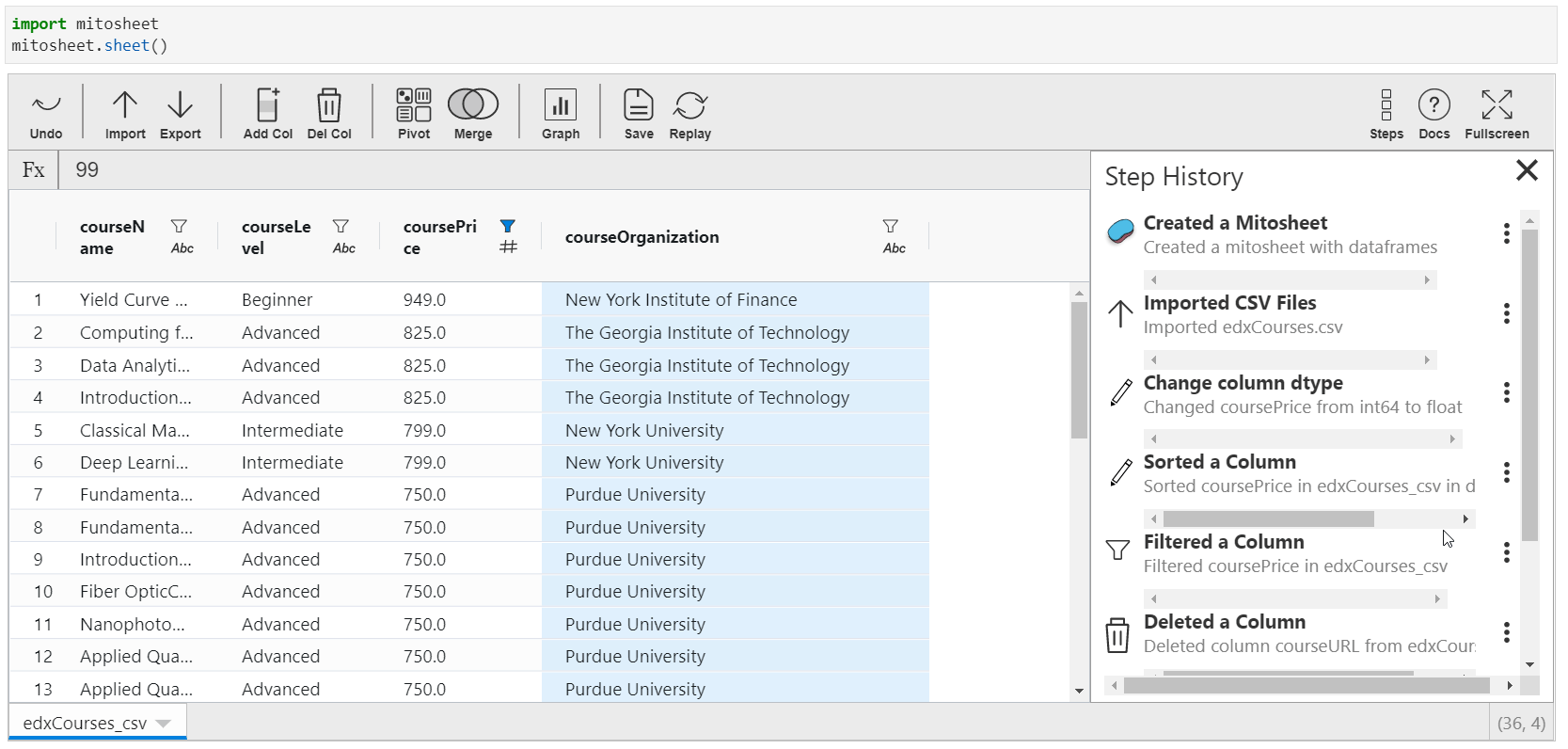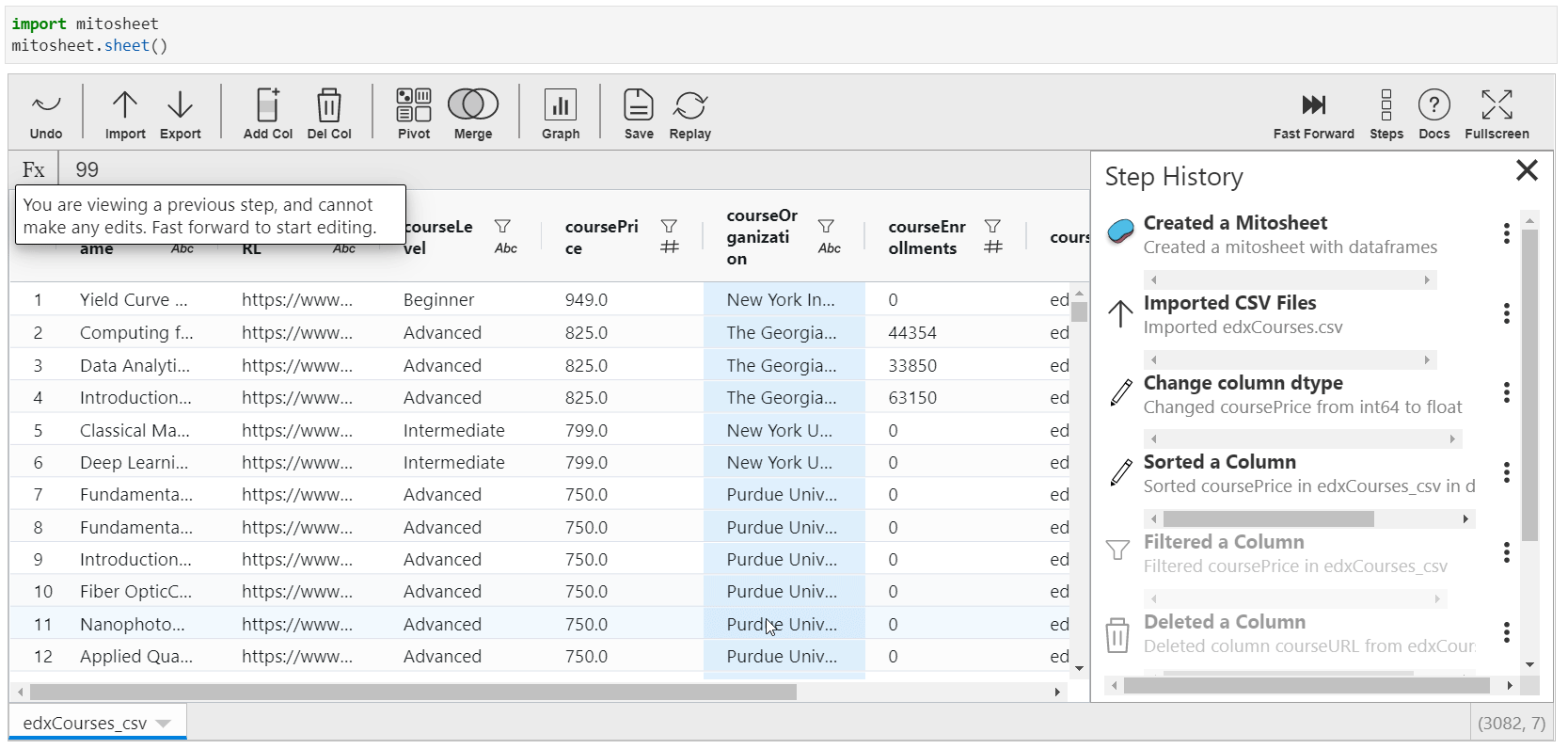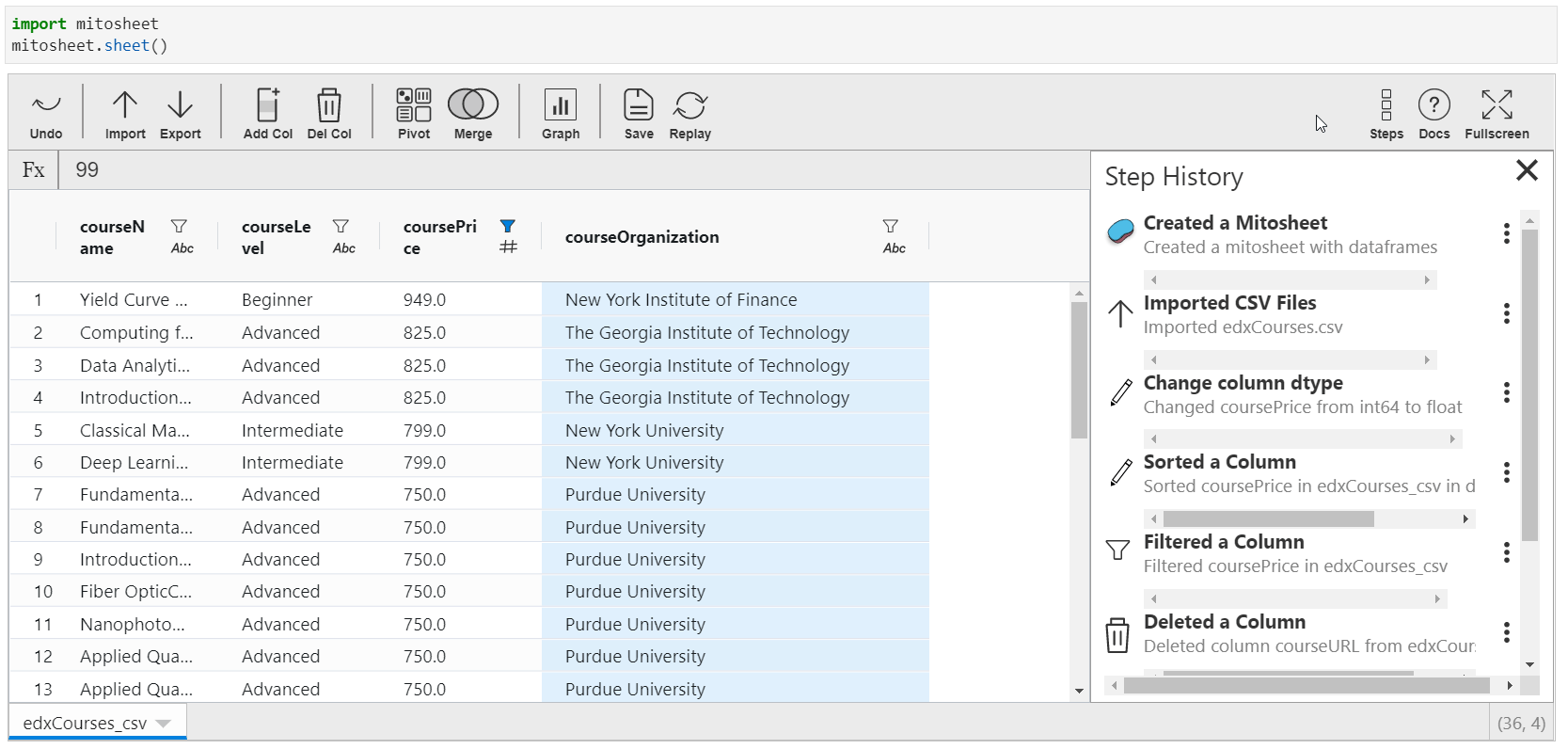
Yous will too find this characteristic in Google's Data Prep tool.
Conclusion
In this article, you got introduced to a new tool "Mito" – one-cease solution for implementing spreadsheet-like functions in a Python surround and getting the equivalent Python code for all the changes made. I explained how to install and debug the installation of Mito, all the features of this extension, and how to utilize them.
If you lot have whatsoever doubts, queries, or potential opportunities, so y'all can reach out to me via
1. Linkedin – in/kaustubh-gupta/
2. Twitter – @Kaustubh1828
iii. GitHub – kaustubhgupta
4. Medium – @kaustubhgupta1828
The media shown in this commodity are not owned past Analytics Vidhya and are used at the Author's discretion.

What Features Make It Easy To Manipulate This Imported Data?,
Source: https://www.analyticsvidhya.com/blog/2021/06/exploring-mito-automatic-python-code-for-spreadsheet-operations/
Posted by: herbertthead1935.blogspot.com
0 Response to "What Features Make It Easy To Manipulate This Imported Data?"
Post a Comment